
コミュニティからのフィードバックに基づき、チームは経済性に関する提案を行っており、最終的な決定に向けてコミュニティの協力を仰いでいます
xx network MainNetの発売で明らかになった課題として、ネットワーク上で低性能なノードが稼働していることが挙げられます。
以前のネットワーク(AlphaNet、BetaNet、ProtoNet)では、こうした問題は、パフォーマンスの悪いノードを無効化することで対処していました。nPoSによって制御されているMainNetでは、これは明らかに不可能です。
MainNetの発売以来、コミュニティはこの問題について議論してきました(#MainNet-chatチャンネルに非常に丁寧なスレッドがあります)。 軋轢).罰則のスライディングスケールを含む解決策などが提案されています。全体として、既存のソリューションに手を加え、クライアント側を修正することが正しいアプローチであるというのが、チームの意見です。
現在の解決策を理解するために、経済学のいくつかの詳細を確認する必要があります。各エポック(24時間)では、一定量のコインが付与される(この決定のメカニズムは xx経済学論文) を獲得し、全ノードに分配する。 このコインのうち、特定のノードに与えられる割合は、獲得したコインの合計の割合に等しくなります。例えば、あるエポックにおいて賞の合計が50,000xxで、あるノードが10,000,000点のうち10,000点を獲得した場合、(10,000/10,000,000)×(50,000xx)=500xxを獲得します(バリデータとノミネータに分配されます)。
しかし、このポイントはどのように獲得するのでしょうか?
xx networkでは、ブロックを作ることと、cMixのラウンドを走ることの2つでポイントを獲得することができます。cMixラウンドを実行する仕組みにこそ、インセンティブの仕組みがあります。
ラウンドが終了するたびに、チーム内の5つのノードが10ポイントを獲得し、リアルタイムフェーズでラウンドが失敗すると、ノードは20ポイントを失います。この失点は、悪い行いを抑制するためのものである。あるノードが原因でラウンドが失敗した場合、なぜすべてのノードがペナルティを受けなければならないのでしょうか?
理由は2つあります。
1つ目は、BFT(Byzantine Fault Tolerance)の下では、cMixプロトコル内で誰が故障しているかを判断することができないことです。つまり、どのノードがポイントを失うべきかを証明することができないのです。
The second is that in the aggregate, other nodes are not penalized. For example, imagine a network with 15 nodes and 5 node teams where all nodes except for one cause 0% of rounds to fail, with one failing 50%. What will happen is that given enough rounds, all good nodes will work with the bad node equally and because points are distributed based upon the total ratio of points, not total points, all “good” nodes will get the same number of xx coins, while the bad node will be penalized. In the above case, a node will be in a team with the bad node 1/3rd of the time. It has a 50% failure rate, so all nodes will have an aggregate 16.667% failure rate. Assuming 100,000 rounds, and each participates in 1/3rd, that means that with the current economics, they will earn 10×100,000×⅓×(1-%16.667) = 277,778 points, and lose 20×100,000×⅓×(%16.667) = 111,111 points, making a total of 166,667 points. While in the same scenario, the offending node will earn 10×100,000×⅓×(%50) = 166,667 and lose 20×100,000×⅓×(%50) = 333,333 points, making a total of -166,667. Points cannot go negative, so the offending nodes get 0 points, and as a result all rewards are split between the other 14 good nodes evenly – as if the offending node was never there.
この解決策はうまくいきますが、例外として、ノードがすべての収益を失うような故障率を目標にしなければなりません。非常に高い信頼性を持つシステムにしたいので、50%よりはるかに高い数値を目標にしたい。
一般に、目標とする故障率と点数の関係式は次のようになる。
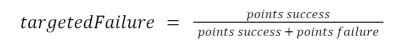
ポイントサクセスが常に10であることを考えると、このようになります。
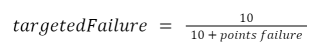
また、地域別の倍率や、失敗したラウンドからノードが回復するまでの時間、ノードのハードウェアやインターネット設定の違いによるラウンド時間への影響も考慮されていないため、これも近似値であると言えます。しかし、現時点での分析には十分です。
残る大きな問題は、適切な「目標とする故障」をどの程度にするかということです。 一般に、ノードの故障率が高く、それを満たさない場合、ポイント、つまり収益は大幅に減少するため、予想以上に高くなることがあります。
過去12時間で、リアルタイム障害率が高いのは以下の通りです。
27.22%, 3.79%, 3.58%, 1.64%, 1.19%
平均故障率0.5%(中央値0.35%)となっています。
このデータから、故障率33%の目標を5%に下げ、リアルタイム故障1件あたりの減点を190にすべきだとチームは考えています。
この問題は、今後数日間、コミュニティでの議論に委ね、12月6日の反響を踏まえて再検討したいと思います。
また、チームが取り組んでいる二次的な応急処置的な解決策もあります。経済的な解決策の究極の欠点は、時間がかかることで、xx messengerや他のxxDkのユーザーによってメッセージが積極的に落とされている場合には、あまり良いことではありません。その結果、チームは現在パフォーマンスの悪いノードオペレータのリストを公開し、xxDKユーザはオプションでそれらのノードを含むラウンドにメッセージを送信しないように選択できるようにする予定です。また、xxDKのユーザは、別途作成された他のリストにも参加することができます。
また、チーム倍率を最低性能の条件とすることも検討しており、近日中に詳細を発表する予定です。


