팀은 예상대로 작동하는지 확인하기 위해 MainNet 이전에 지역 승수에 대한 최종 테스트를 실행하고 있습니다.
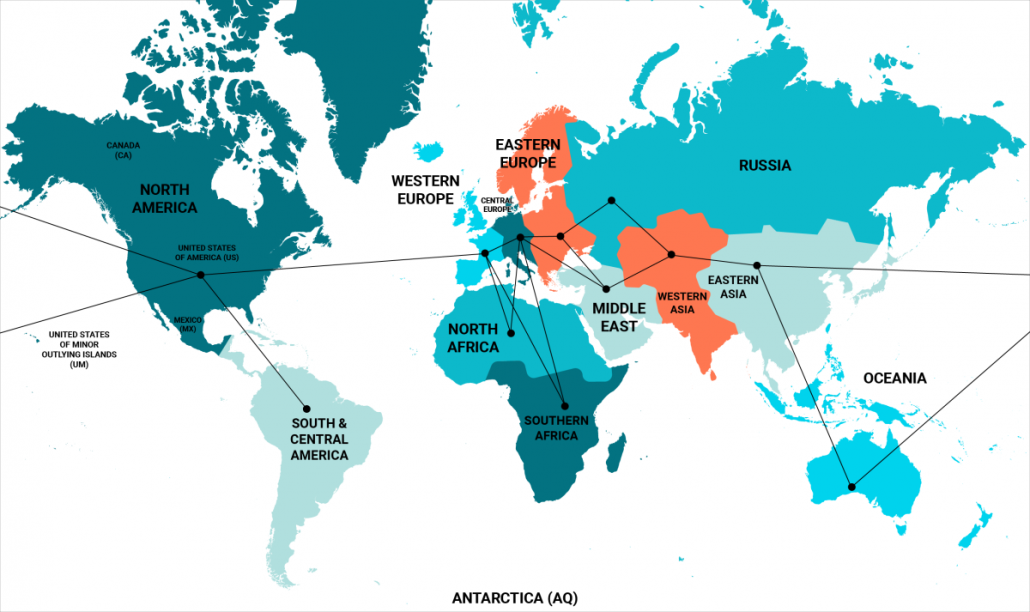
2주 전에 우리는 지리적 빈에 대한 업데이트를 발표했으며 이것이 지역 승수에 대한 테스트에 반영될 것이라고 발표했습니다. 그 때가 왔습니다. 지난 주 데이터를 사용하여 모든 지역에 대한 새로운 승수를 계산했습니다.

이러한 승수를 사용하여 다양한 지역에서 노드를 실행하기 위한 대기 시간 요소를 상쇄해야 합니다.
이것은 불완전한 시스템입니다. 노드가 하나뿐인 중동과 같은 지역은 일반적인 성능을 제대로 설명하지 못하는 결과를 읽고 있습니다. 북아프리카와 같은 다른 지역에는 노드가 전혀 없으므로 해당 값을 추측해야 합니다.
그러나 더 큰 문제는 올바른 승수가 지역에 있는 노드 수의 함수라는 것입니다. 네트워크를 설계할 때 지역의 모든 노드가 팀의 모든 노드 중 가장 높은 승수를 경험하도록 만들었습니다. 이는 노드 운영자가 라운드에 참여하지 않도록 인센티브를 받는 경우가 없도록 하기 위한 것입니다. 결과적으로 주어진 영역에 대한 올바른 승수는 해당 영역에 있는 노드 수의 함수입니다.
이는 네트워크가 성장하고 축소됨에 따라 승수를 정기적으로 업데이트해야 함을 의미합니다. 아래에서 볼 수 있듯이 승수에 대한 수학은 비교적 규칙적이므로 어느 시점에서 체인에 통합하고 매 시대마다 자동으로 계산하는 것이 가능할 수 있습니다.
이 솔루션은 또한 승수가 처리되는 방식을 조정해야 합니다. 원래 팀의 모든 노드는 동일한 승수를 상속했습니다. 그 결과 매우 이상한 승수가 나왔으므로 모든 노드에 자체 승수의 평균과 팀 내 최고치를 제공하도록 알고리즘을 조정하고 있습니다.
승수 계산
승수를 계산할 때 승수를 제외한 모든 시대에 각 노드가 얻은 점수인 원시 숫자로 시작했습니다. 우리는 모든 것이 공정하기를 원하며 각 노드 러너가 다른 모든 노드와 팀을 이루도록 장려되기를 바랍니다. 따라서 우리의 목표는 완전한 참여가 네트워크에서 완전한 "포인트"를 얻도록 하는 것입니다.
계속하기 전에 몇 가지 정의:
- Mᵢ – Bin의 모든 노드에 대한 승수 나.
- Aᵢ – Bin에 대한 조정된 포인트 값 나.
- Pᵢ – bin에서 하나 이상의 노드가 나올 확률 나 팀에 포함되어 있고 모든 bin의 노드 <나 포함되지 않습니다.
계산은 실제 네트워크 데이터를 기반으로 합니다. 지난 주에 우리는 노드당 한 시대에 cMix 작업에 대해 평균 점수를 얻었습니다. 그런 다음 이것은 Aᵢ으로 알려진 빈에 대한 조정된 포인트 값을 생성하기 위해 "정규화"되었습니다.
이 시스템의 목표는 미래의 As가 모두 1이 되도록 승수를 만드는 것입니다.
빈은 A에 의해 최소에서 최대로 정렬됩니다. 포인트를 계산할 때 모든 노드의 승수는 승수의 평균이며 팀에서 가장 높은(또한 가장 낮은 i)입니다.
평균이 가장 낮은 영역인 Bin 0이 다른 모든 영역을 덮어쓰므로 Bin 0의 승수는 다음과 같이 계산할 수 있습니다.

우리의 목표는 모든 팀의 모든 노드에 대한 승수 및 조정도 평균 최대 1이 되도록 하는 것입니다. Mₙ는 n번째 빈에 대한 승수이고 Aₙ는 n번째 빈에 대한 정규화된 평균이기 때문입니다. 이것은 쉽게 해결할 수 있습니다.
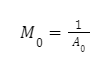
Bin 1의 다음 승수는 Bin 1의 노드가 Bin 0의 노드(M0 Bin 승수 사용)와 선택될 확률과 Bin 1의 노드가 Bin의 노드와 팀을 이루지 않을 확률로 계산할 수 있습니다. 0(M1 팀 승수 사용):
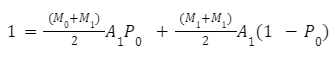
Bin 2에 대해서도 동일한 계산을 수행할 수 있습니다.
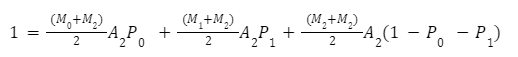
Bin에 대해 이러한 방정식은 풀 수 있으며 승수로 정의할 수 있습니다. Bin 2의 경우 승수를 계산하기 위한 변환은 다음과 같습니다.
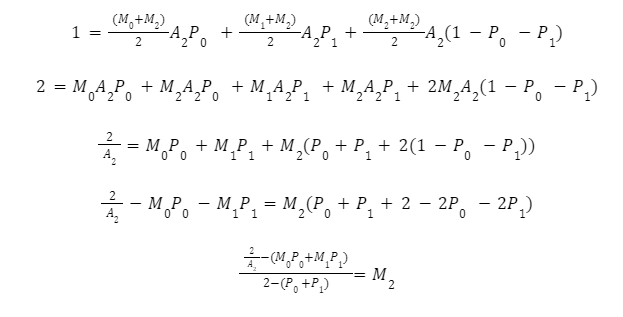
팀 승수 Bin n에 대한 합계를 사용하여 이것을 일반화할 수 있습니다.
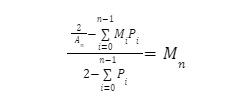
재귀적 정의 외에도 확률을 맞추는 것은 까다롭습니다. 5개 노드로 구성된 팀의 각 선택은 네트워크의 총 노드에서 교체 없이 무작위 추첨으로 구성됩니다. 이러한 종류의 선택은 초기하 분포로 설명됩니다. 가장 빈번하게, 이 분포는 바이너리 기능(예를 들어, BFT 합의 영역: 비잔틴/정직한 노드)으로 객체(이 경우 노드)를 계산하는 간단한 경우에 적용됩니다. 그러나 cMix에서는 노드를 12개의 빈으로 분할하여 문제를 다차원 문제로 바꾸므로 다변량 초기하 분포를 계산해야 합니다. 운 좋게도 승수가 작동하는 방식의 특성으로 인해 빈 2에서 노드를 선택할 때 팀의 다른 노드가 더 높은 승수를 가진 빈에 속하는지 여부는 신경 쓰지 않습니다. 이것은 우리가 계산해야 하는 모든 확률이 비슷하다는 것을 의미합니다. 모든 bin의 노드가 없는 bin i의 노드가 하나 이상 있는 팀을 원합니다. <i. We include a spreadsheet in our resources below which show how to do this in detail.
오류
이 솔루션은 A 값의 불일치가 선택 확률에 영향을 미치는 라운드 소요 시간의 변화로 인해 상당 부분 발생한다는 사실로 인해 약간의 오류가 있습니다. 시뮬레이션에서 설명한 이 솔루션은 3% 내에서 정확합니다. 향후 작업에서는 더 나은 모델링을 위해 점 변동의 원인을 분해하고 이 오류를 줄일 수 있습니다.
자원:
쓰레기통 목록:
스케줄링 알고리즘: https://git.xx.network/xx_network/primitives/-/blob/dev/region/ordering.go
승수 계산:
https://docs.google.com/spreadsheets/d/1d2HcuCVorKDkUppBam-dk-_PJ8ukPp8ja18DyE_VYJQ/edit?usp=sharing
계산을 확인하기 위한 시뮬레이션용 Python 스크립트:


