Команда проводит финальные тесты региональных множителей перед MainNet, чтобы убедиться, что они работают так, как ожидается
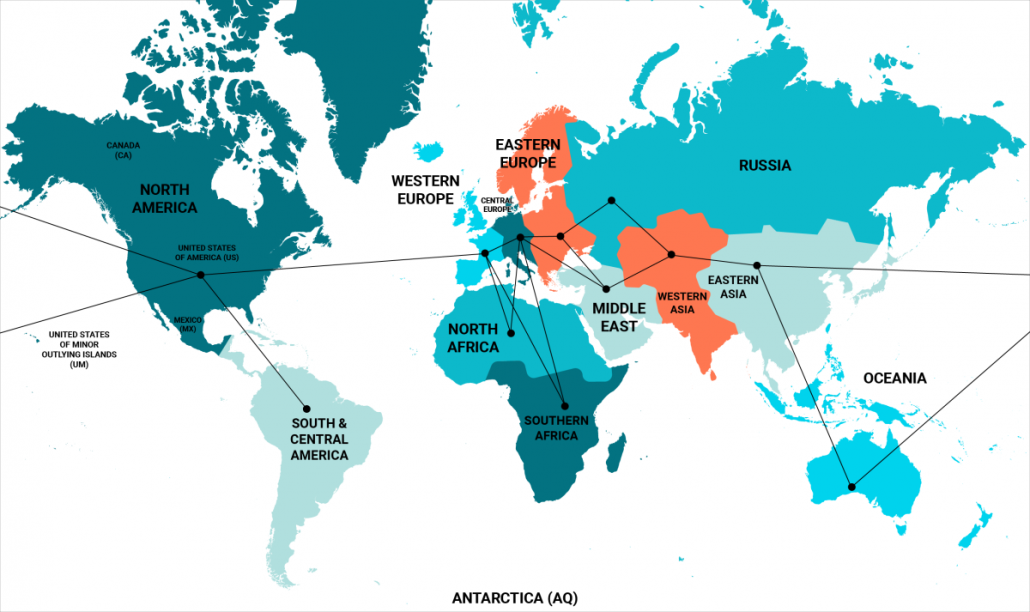
Две недели назад мы объявили об обновлении географических бинов и о том, что это послужит основой для тестирования региональных мультипликаторов - это время настало. Используя данные прошлой недели, мы рассчитали новые мультипликаторы для каждого региона:

С помощью этих множителей мы должны компенсировать коэффициенты задержки при работе узлов в различных регионах.
Это несовершенная система. Регионы, такие как Ближний Восток, имеющие только один узел, получают результаты, которые не совсем точно описывают их общую производительность. Другие регионы, например, Северная Африка, вообще не имеют узлов, и поэтому их значения придется угадывать.
Но еще большая проблема заключается в том, что правильный множитель зависит от того, сколько узлов имеет регион. При проектировании сети мы сделали так, чтобы каждый узел в регионе имел самый высокий множитель среди всех узлов в команде. Это сделано для того, чтобы никогда не возникло ситуации, когда операторы узлов имеют стимул не участвовать в раунде. В результате правильный множитель для данного региона зависит от количества узлов в этом регионе.
Это означает, что множители необходимо будет регулярно обновлять по мере роста и сокращения сети. Как можно видеть ниже, математика для множителей относительно обычна, поэтому, возможно, в какой-то момент ее можно будет интегрировать в цепочку и автоматически вычислять ее каждую эпоху.
Это решение также требует корректировки работы с множителями. Первоначально все узлы в команде наследовали одинаковые множители. Это приводило к очень странным множителям, поэтому мы скорректировали алгоритм, чтобы все узлы получали среднее значение своего собственного множителя и самого высокого в команде.
Вычисление множителей
При расчете множителей мы начали с исходных цифр - сколько очков получил каждый узел в каждой эпохе без учета множителя. Мы хотим, чтобы все было честно, и чтобы у каждого узла-бегуна был стимул объединяться с каждым другим узлом. Таким образом, наша цель - убедиться, что полное участие дает вам полные "очки" в сети.
Прежде чем мы продолжим, несколько определений:
- Mᵢ - Множитель для всех узлов в Bin i.
- Aᵢ - Скорректированное значение баллов для Bin i.
- Pᵢ - вероятность того, что хотя бы один узел из бина i входит в команду, а узел из любого бина <i не входит.
Вычисления производятся на основе реальных сетевых данных. За последнюю неделю мы получили среднее количество баллов, заработанных за операции cMix в эпоху на каждом узле. Затем этот показатель был "нормализован" для получения скорректированного значения баллов для бина, известного как Aᵢ.
Цель этой системы - создать такие множители, чтобы будущие As были равны 1.
Банки упорядочены от минимального до максимального по A. При подсчете очков множитель каждого узла равен среднему значению его множителя и самого высокого в команде (также самого низкого i).
Поскольку регион с наименьшим средним значением, Бин 0, перекрывает все остальные, множитель Бин 0 может быть рассчитан как:

Наша цель состоит в том, чтобы множители и корректировки для всех узлов во всех командах в среднем также были максимальны и равны 1. Поскольку Mₙ - множитель для n-го упорядоченного бина, а Aₙ - нормализованное среднее для n-го упорядоченного бина. Это можно легко решить:
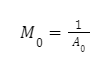
Следующий множитель для корзины 1 может быть рассчитан как вероятность того, что узел из корзины 1 будет выбран вместе с узлом из корзины 0 (при этом используется множитель корзины M0) и вероятность того, что узел из корзины 1 не будет связан с узлом из корзины 0 (при этом используется множитель команды M1):
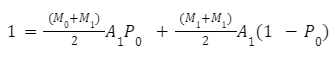
Мы можем сделать такой же расчет для Бина 2:
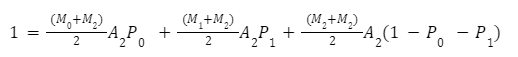
Эти уравнения для любого бина разрешимы и могут быть определены в терминах множителя. Для бина 2 преобразования для вычисления множителя следующие:
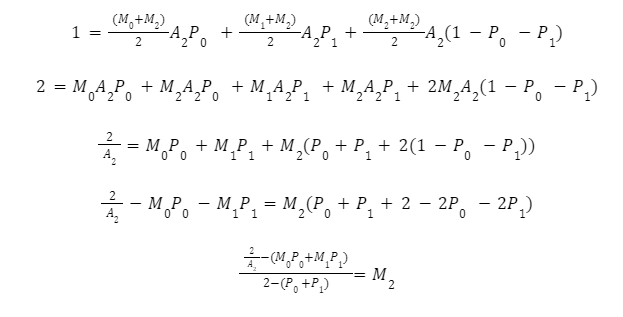
Мы можем обобщить это, используя суммирование для любого командного множителя Bin n:
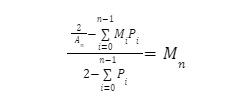
В дополнение к рекурсивному определению, вероятности сложно правильно определить. Каждый выбор команды из 5 узлов состоит из случайной выборки, без замены, из общего числа узлов в сети. Такой выбор описывается гипергеометрическим распределением. Чаще всего это распределение применяется к простому случаю подсчета объектов (узлов в нашем случае) с бинарным признаком (например, в сфере консенсуса BFT: византийские/честные узлы). Однако в cMix мы разделили узлы на 12 бинов, что превращает проблему в многомерную, а значит, нам нужно вычислить многомерное гипергеометрическое распределение. К счастью, благодаря природе работы множителей, когда мы выбираем узел, скажем, из бина 2, нас не волнует, принадлежит ли какой-либо другой узел в команде к бину с более высоким множителем. Это означает, что все вероятности, которые нам нужно вычислить, аналогичны: мы хотим, чтобы в команде был хотя бы один узел из корзины i, без каких-либо узлов из всех корзин <i. Мы включили в наши ресурсы ниже электронную таблицу, в которой подробно показано, как это сделать.
Ошибка
Это решение имеет некоторые ошибки из-за того, что расхождения в значениях A в значительной степени вызваны различиями в продолжительности раундов, что влияет на вероятность выбора. Это решение, описанное нашим моделированием, верно в пределах 3%. В будущей работе можно разложить причины вариаций очков, чтобы лучше смоделировать их и уменьшить эту ошибку.
Ресурсы:
Список бункеров:
Алгоритм составления расписания: https://git.xx.network/xx_network/primitives/-/blob/dev/region/ordering.go
Расчет множителя:
https://docs.google.com/spreadsheets/d/1d2HcuCVorKDkUppBam-dk-_PJ8ukPp8ja18DyE_VYJQ/edit?usp=sharing
Python-скрипт для симуляций для подтверждения расчетов:


