Команда проводить фінальні випробування регіональних мультиплікаторів перед MainNet, щоб переконатися, що вони діють так, як очікувалося
Два тижні тому ми анонсували оновлення географічних кошиків, і що це стане основою для тестування регіональних мультиплікаторів - цей час настав. Використовуючи дані за минулий тиждень, ми розрахували нові мультиплікатори для кожного регіону:

За допомогою цих мультиплікаторів ми повинні нівелювати фактори затримки запуску вузлів у різних регіонах.
Це недосконала система. Регіони, такі як Близький Схід, які мають лише один вузол, отримують результати, які насправді не описують їх загальну ефективність. Інші регіони, такі як Північна Африка, взагалі не мають вузлів, і, як наслідок, їхні значення доведеться вгадувати.
Але ще більший виклик полягає в тому, що правильний мультиплікатор залежить від того, скільки вузлів має регіон. При розробці мережі ми зробили так, щоб кожен вузол в регіоні мав найвищий мультиплікатор, ніж будь-який вузол в команді. Це зроблено для того, щоб ніколи не було випадків, коли оператори вузлів будуть зацікавлені не брати участь у раунді. В результаті, правильний мультиплікатор для даного регіону є функцією від кількості вузлів в цьому регіоні.
Це означає, що мультиплікатори потрібно буде регулярно оновлювати по мірі зростання та скорочення мережі. Як можна побачити нижче, математика для мультиплікаторів є відносно регулярною, тому може бути можливим інтегрувати її в ланцюжок в певний момент і автоматично розраховувати її кожну епоху.
Це рішення також вимагає коригування способу роботи з множниками. Спочатку всі вузли в команді успадкували однакові множники. Це призвело до дуже дивних множників, тому ми коригуємо алгоритм, щоб дати всім вузлам середнє значення їх власного множника і найвищого в команді.
Розрахунок мультиплікаторів
При розрахунку множників ми відштовхувалися від сирих чисел, скільки балів отримав кожен вузол в кожну епоху без урахування множника. Ми хочемо, щоб все було чесно, і ми хочемо, щоб кожен учасник був зацікавлений в об'єднанні з кожним іншим вузлом. Отже, наша мета - зробити так, щоб повна участь приносила вам повні "бали" в мережі.
Перш ніж продовжити, кілька визначень:
- Mᵢ - множник для всіх вузлів у Bin i.
- Aᵢ - скориговане значення точки для Bin i.
- Pᵢ - ймовірність того, що хоча б одна вершина з bin i включається в команду, а вузол з будь-якого біну <i не включено.
Розрахунок виконано на реальних даних мережі. За останній тиждень ми отримали середні бали, зароблені за операції cMix в епоху на кожен вузол. Потім це було "нормалізовано" для отримання скоригованого значення балів для біна, відомого як Aᵢ.
Мета цієї системи - створити такі Мультиплікатори, щоб у майбутньому Ас був 1.
Кошики впорядковані від мінімального до максимального за A. При підрахунку балів множник кожного вузла є середнім між його множником та найбільшим у команді (також найменшим i).
Оскільки регіон з найнижчим середнім показником, Bin 0, перекриває всі інші, мультиплікатор Bin 0 може бути розрахований як:

Наша мета полягає в тому, щоб мультиплікатори та поправки для всіх вузлів у всіх командах також в середньому були максимальними і не перевищували 1. Оскільки Mₙ - це мультиплікатор для n-го впорядкованого відсіку, а Aₙ - це нормалізоване середнє для n-го впорядкованого відсіку. Цю задачу легко розв'язати:
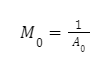
Наступний мультиплікатор для Bin 1 може бути розрахований як ймовірність того, що вузол з Bin 1 буде обраний з вузлом з Bin 0 (для цього використовується мультиплікатор bin M0) та ймовірність того, що вузол з Bin 1 не буде об'єднаний з вузлом з Bin 0 (для цього використовується мультиплікатор об'єднання M1):
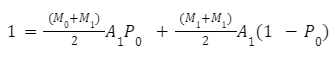
Такий самий розрахунок ми можемо зробити і для Урни 2:
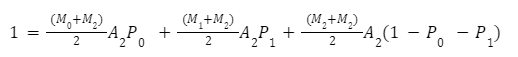
Ці рівняння для будь-якого Bin є розв'язними і можуть бути визначені в термінах мультиплікатора. Для Bin 2 перетворення для обчислення множника мають вигляд:
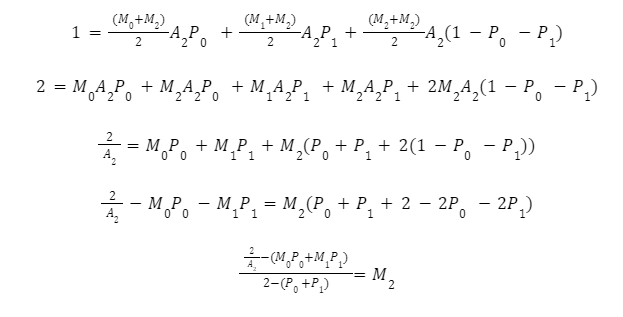
Ми можемо узагальнити це за допомогою підсумовування для будь-якого множника команди Bin n:
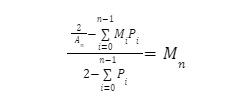
На додаток до рекурсивного визначення, ймовірності є складними для правильного визначення. Кожен вибір команди з 5 вузлів складається з випадкового жеребкування, без заміни, із загальної кількості вузлів у мережі. Такий відбір описується гіпергеометричним розподілом. Найчастіше цей розподіл застосовується до простого випадку підрахунку об'єктів (вузлів у нашому випадку) з бінарною ознакою (наприклад, в області консенсусу BFT: візантійські/чесні вузли). Однак в cMix ми розбили вузли на 12 бінів, що перетворює задачу на багатовимірну, тобто нам потрібно обчислити багатовимірний гіпергеометричний розподіл. На щастя, через природу роботи множників, коли ми вибираємо вузол, скажімо, з біна 2, нам байдуже, чи є будь-який інший вузол в команді з біна, який має більший множник. Це означає, що всі ймовірності, які нам потрібно обчислити, схожі: ми хочемо мати команду, в якій є принаймні один вузол з біну i, без жодного вузла з усіх бінів <i. Нижче ми додаємо до наших ресурсів електронну таблицю, яка детально показує, як це зробити.
Помилка
Це рішення має деякі помилки через те, що розбіжності у значеннях A значною мірою спричинені варіаціями тривалості раундів, які впливають на ймовірність відбору. Це рішення, як описано в нашому моделюванні, є правильним з точністю до 3%. Подальша робота може бути спрямована на деконструкцію причин варіацій точок для кращого їх моделювання та зменшення цієї похибки.
Ресурси:
Перелік контейнерів:
Алгоритм планування: https://git.xx.network/xx_network/primitives/-/blob/dev/region/ordering.go
Розрахунок мультиплікатора:
https://docs.google.com/spreadsheets/d/1d2HcuCVorKDkUppBam-dk-_PJ8ukPp8ja18DyE_VYJQ/edit?usp=sharing
Python-скрипт для моделювання для підтвердження розрахунків:


