
根据社区的反馈,该团队有一个关于经济学的建议,并希望社区能够帮助做出最终决定。
随着xx network MainNet的推出,一个问题已经暴露出来,即有一些性能较低的节点在网络上运行。
在网络的前几代产品中--AlphaNet、BetaNet和ProtoNet--这些问题都是由团队通过简单地禁用性能差的节点来处理的。这在由nPoS控制的MainNet中显然是不可能的。
自MainNet发布以来,社区一直在讨论这个问题(你可以在#MainNet-聊天频道中找到一个非常周到的主题 不和).有人提出了涉及滑动惩罚尺度的解决方案,其中包括。总的来说,团队认为,对现有的解决方案进行调整,再加上客户端的修改,是正确的方法。
为了理解当前的解决方案,需要审查经济学的一些细节。在每个纪元(24小时)中,都会有一定数量的硬币被授予(这个决定的机制在《世界经济展望》中有所描述)。 xx 经济学论文)并在所有节点之间分配。 奖励给特定节点的这些硬币的部分等于他们在总的硬币赚取的部分。例如,如果在一个纪元的奖励总额为50,000xx,而一个特定的节点在总共10,000,000中得到10,000分,他们将得到(10,000/10,000,000)×(50,000xx)=500xx(由验证人和提名人分担)。
但这些积分是如何获得的呢?
在xx network中,有两件事可以获得积分:制作区块和运行cMix回合。激励计划就在运行cMix回合的机制中。
每当一个回合完成后,团队中的5个节点都会获得10分,而当一个回合在实时阶段失败时,节点会损失20分。这种积分的损失是为了抑制不良行为。起初,这似乎很不公平--如果一个回合由于一个节点而失败,为什么每个节点都要受到惩罚?
有两个原因。
首先是在BFT(拜占庭容错)下,不可能确定谁在cMix协议中犯错。这意味着不可能证明哪个节点应该丢分。
The second is that in the aggregate, other nodes are not penalized. For example, imagine a network with 15 nodes and 5 node teams where all nodes except for one cause 0% of rounds to fail, with one failing 50%. What will happen is that given enough rounds, all good nodes will work with the bad node equally and because points are distributed based upon the total ratio of points, not total points, all “good” nodes will get the same number of xx coins, while the bad node will be penalized. In the above case, a node will be in a team with the bad node 1/3rd of the time. It has a 50% failure rate, so all nodes will have an aggregate 16.667% failure rate. Assuming 100,000 rounds, and each participates in 1/3rd, that means that with the current economics, they will earn 10×100,000×⅓×(1-%16.667) = 277,778 points, and lose 20×100,000×⅓×(%16.667) = 111,111 points, making a total of 166,667 points. While in the same scenario, the offending node will earn 10×100,000×⅓×(%50) = 166,667 and lose 20×100,000×⅓×(%50) = 333,333 points, making a total of -166,667. Points cannot go negative, so the offending nodes get 0 points, and as a result all rewards are split between the other 14 good nodes evenly – as if the offending node was never there.
这个解决方案确实可行,但例外的是,它必须以节点应失去所有收益的故障率为目标。鉴于我们希望系统具有非常高的可靠性,我们希望目标数字远远高于50%。
一般来说,与目标故障率和点数有关的方程式如下。
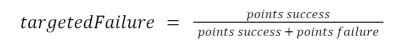
鉴于积分成功率总是10,这就给了我们。
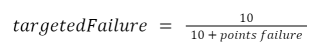
这也是一个近似值,因为它没有考虑到区域乘数、节点从失败的回合中恢复所需的时间,也没有考虑到不同的节点硬件和互联网配置可能对回合时间的影响。但是,这对目前的分析是足够的。
剩下的大问题是,适当的 "目标故障 "应该是什么。 一般来说,它可以比人们预期的要高,因为当一个节点的高故障率没有达到它时,积分,也就是收益仍然会大幅下降。
在过去12小时内,最高的实时故障率如下。
27.22%, 3.79%, 3.58%, 1.64%, 1.19%
平均故障率为0.5%(中位数为0.35%)。
鉴于这些数据,团队认为我们应该把目标从33%的故障率降低到5%,这将使每次实时故障的扣分达到190分。
我们希望在接下来的几天里开放这个问题供社区讨论,并将根据2021年12月6日的反应重新讨论这个问题。
还有一个次要的权宜之计,该团队正在研究。经济解决方案的最终缺陷是它们可能需要时间,当消息被xx messenger和xxDk的其他用户主动放弃时,这不是很好。因此,该团队将公布一个目前表现不佳的节点运营商名单,xxDK用户可以选择不在包含这些节点的回合中发送消息。xxDK用户也可以选择加入其他单独策划的列表。
该团队还将研究使团队乘数取决于最低业绩,更多信息即将公布。


