Das Team führt vor der MainNet letzte Tests mit den regionalen Multiplikatoren durch, um sicherzustellen, dass sie wie erwartet funktionieren.
Vor zwei Wochen haben wir angekündigt, dass wir die geografischen Abgrenzungen aktualisieren und die regionalen Multiplikatoren testen werden - jetzt ist es so weit. Anhand der Daten von letzter Woche haben wir neue Multiplikatoren für jede Region berechnet:

Mit diesen Multiplikatoren sollten wir die Latenzfaktoren für den Betrieb von Knotenpunkten in verschiedenen Regionen ausgleichen.
Dieses System ist unvollkommen. Regionen wie der Nahe Osten, die nur einen Knotenpunkt haben, erhalten Ergebnisse, die nicht wirklich ihre allgemeine Leistung widerspiegeln. Andere Regionen, wie Nordafrika, haben überhaupt keine Knotenpunkte und müssen daher ihre Werte schätzen lassen.
Eine noch größere Herausforderung ist jedoch, dass der richtige Multiplikator davon abhängt, wie viele Knotenpunkte eine Region hat. Bei der Entwicklung des Netzwerks haben wir darauf geachtet, dass jeder Knotenpunkt in einer Region den höchsten Multiplikator aller Knotenpunkte im Team hat. Damit soll sichergestellt werden, dass es keinen Anreiz für die Betreiber der Knotenpunkte gibt, nicht an einer Runde teilzunehmen. Daher ist der richtige Multiplikator für eine bestimmte Region eine Funktion der Anzahl der Knotenpunkte in dieser Region.
Das bedeutet, dass die Multiplikatoren regelmäßig aktualisiert werden müssen, wenn das Netzwerk wächst und schrumpft. Wie unten zu sehen ist, ist die Berechnung der Multiplikatoren relativ regelmäßig, so dass es möglich sein könnte, sie irgendwann in die Kette zu integrieren und sie automatisch für jede Ära zu berechnen.
Diese Lösung erfordert auch eine Anpassung der Handhabung von Multiplikatoren. Ursprünglich hatten alle Knoten in einem Team die gleichen Multiplikatoren. Das führte zu sehr seltsamen Multiplikatoren. Deshalb passen wir den Algorithmus so an, dass alle Knoten den Durchschnitt ihres eigenen Multiplikators und des höchsten im Team erhalten.
Berechnung der Multiplikatoren
Bei der Berechnung der Multiplikatoren haben wir mit den rohen Zahlen begonnen, also damit, wie viele Punkte jeder Knotenpunkt in jeder Ära ohne den Multiplikator erhalten hat. Wir wollen, dass alles fair ist und dass jeder Knotenpunktläufer einen Anreiz hat, mit jedem anderen Knotenpunkt zusammenzuarbeiten. Unser Ziel ist es also, sicherzustellen, dass du bei voller Teilnahme die vollen "Punkte" im Netzwerk bekommst.
Bevor wir fortfahren, einige Definitionen:
- Mᵢ - Der Multiplikator für alle Knotenpunkte in Bin i.
- Aᵢ - Der angepasste Punktwert für Bin i.
- Pᵢ - Die Wahrscheinlichkeit, dass mindestens ein Knoten aus bin i in ein Team aufgenommen wird, und ein Knoten aus einem beliebigen bin <i ist nicht enthalten.
Die Berechnung wird mit realen Netzwerkdaten gespeist. In der letzten Woche haben wir die durchschnittlichen Punkte für cMix-Operationen in einer Ära pro Knotenpunkt erhalten. Dieser Wert wurde dann "normalisiert", um den angepassten Punktwert für den Bin zu erhalten, der als Aᵢ bekannt ist.
Das Ziel dieses Systems ist es, Multiplikatoren so zu erstellen, dass zukünftige As alle 1 sind.
Bei der Berechnung der Punkte ist der Multiplikator jedes Knotens der Durchschnitt aus seinem Multiplikator und dem höchsten im Team (also dem niedrigsten i).
Da die Region mit dem niedrigsten Durchschnitt, Bin 0, alle anderen überschreibt, kann der Multiplikator von Bin 0 wie folgt berechnet werden:

Unser Ziel ist es, sicherzustellen, dass die Multiplikatoren und Anpassungen für alle Knotenpunkte in allen Teams im Durchschnitt ebenfalls maximal 1 sind. Denn Mₙ ist der Multiplikator für die n-te geordnete Tonne und Aₙ ist der normalisierte Durchschnitt für die n-te geordnete Tonne. Dies kann leicht gelöst werden:
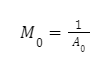
Der nächste Multiplikator für Bin 1 kann berechnet werden als die Wahrscheinlichkeit, dass ein Knoten aus Bin 1 mit einem Knoten aus Bin 0 ausgewählt wird (dabei wird der M0-Bin-Multiplikator verwendet) und die Wahrscheinlichkeit, dass ein Knoten aus Bin 1 nicht mit einem Knoten aus Bin 0 gepaart wird (dabei wird der M1-Team-Multiplikator verwendet):
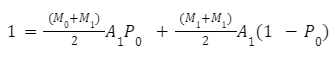
Wir können die gleiche Berechnung für Bin 2 durchführen:
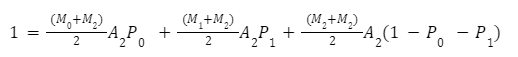
Diese Gleichungen sind für jeden Bin lösbar und können mit Hilfe des Multiplikators definiert werden. Für Bin 2 lauten die Umformungen zur Berechnung des Multiplikators:
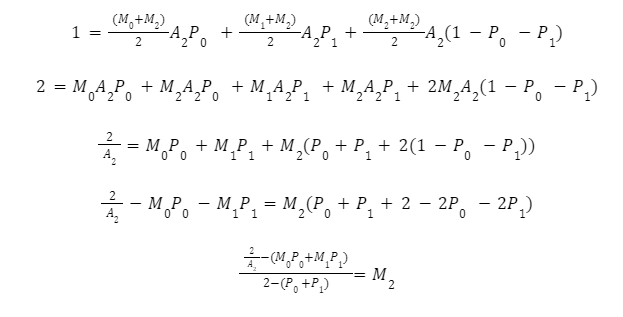
Wir können dies verallgemeinern, indem wir Summen für jeden Team-Multiplikator Bin n bilden:
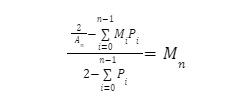
Neben der rekursiven Definition sind auch die Wahrscheinlichkeiten knifflig zu verstehen. Jede Auswahl eines Teams von 5 Knoten besteht aus einer zufälligen, ersatzlosen Ziehung aus der Gesamtheit der Knoten im Netzwerk. Diese Art der Auswahl wird durch eine hypergeometrische Verteilung beschrieben. Meistens wird diese Verteilung auf einen einfachen Fall angewandt, bei dem Objekte (in unserem Fall Knoten) mit einem binären Merkmal gezählt werden (zum Beispiel im Bereich des BFT-Konsenses: byzantinische/ehrliche Knoten). In cMix haben wir die Knoten jedoch in 12 Bins aufgeteilt, was das Problem in ein mehrdimensionales verwandelt und bedeutet, dass wir eine multivariate hypergeometrische Verteilung berechnen müssen. Glücklicherweise liegt es in der Natur der Multiplikatoren, dass es uns bei der Auswahl eines Knotens, z. B. aus Feld 2, egal ist, ob ein anderer Knoten im Team zu einem Feld mit einem höheren Multiplikator gehört. Das bedeutet, dass alle Wahrscheinlichkeiten, die wir berechnen müssen, ähnlich sind: Wir wollen ein Team mit mindestens einem Knoten aus Feld i haben, ohne Knoten aus allen Feldern <i. In unseren Ressourcen unten findest du eine Tabelle, die dir zeigt, wie du das im Detail machen kannst.
Fehler
Diese Lösung ist mit einigen Fehlern behaftet, da die Diskrepanzen bei den A-Werten größtenteils auf die unterschiedliche Dauer der Runden zurückzuführen sind, die sich auf die Auswahlwahrscheinlichkeit auswirkt. Die von unserer Simulation beschriebene Lösung ist mit einer Genauigkeit von 3% korrekt. Zukünftige Arbeiten können die Ursachen der Punktabweichungen aufschlüsseln, um sie besser zu modellieren und diesen Fehler zu reduzieren.
Ressourcen:
Liste der Lagerplätze:
Zeitplanungsalgorithmus: https://git.xx.network/xx_network/primitives/-/blob/dev/region/ordering.go
Berechnung des Multiplikators:
https://docs.google.com/spreadsheets/d/1d2HcuCVorKDkUppBam-dk-_PJ8ukPp8ja18DyE_VYJQ/edit?usp=sharing
Python-Skript für Simulationen zur Bestätigung der Berechnungen:


