The team is running final tests on the Regional Multipliers before MainNet to make sure they act as expected
Two weeks ago, we announced updates to the geographic bins, and that this would feed into a test for the regional multipliers — that time has come. Using last week’s data, we computed new multipliers for every region:

With these multipliers, we should offset the latency factors for running nodes in various regions.
This is an imperfect system. Regions, like the Middle East, which only have one node, are reading results which are properly not really descriptive of their general performance. Other regions, like North Africa have no nodes at all, and as a result will have to have their values guessed at.
But, an even bigger challenge is that the correct multiplier is a function of how many nodes a region has. When designing the network, we made it so that every node in a region experienced the highest multiplier of any node in the team. This is to ensure there never is a case where node operators are incentivized to not participate in a round. As a result, the correct multiplier for a given region is a function of the number of nodes in that region.
This means that multipliers will need to be updated on a regular basis as the network grows and shrinks. As can be seen below, the math for multipliers is relatively regular, so it may be possible to integrate it on-chain at some point and automatically calculate it every era.
This solution also requires adjusting how multipliers are handled. Originally, all nodes in a team inherited the same multipliers. This resulted in some very odd multipliers, so we are adjusting the algorithm to give all nodes the average of their own multiplier and the highest in the team.
Calculating the Multipliers
When calculating the multipliers, we started with the raw numbers, how many points each node got in every era excluding the multiplier. We want everything to be fair, and we want each node runner to be incentivized to team with every other node. So, our goal is to make sure that full participation gets you full “points” in the network.
Before we continue, some definitions:
- Mᵢ – The multiplier for all nodes in Bin i.
- Aᵢ – The adjusted point value for Bin i.
- Pᵢ – The probability that at least one node from bin i is included in a team, and a node from any bin <i is not included.
The calculation is seeded by real network data. Over the last week, we got the average points earned for cMix operations in an era per node. This was then “normalized” to produce the adjusted point value for the bin, known as Aᵢ.
The goal of this system is to create Multipliers such that future As will all be 1.
Bins are ordered minimum to maximum by A. When calculating points, every node’s multiplier is the average of their multiplier and the highest in the team (also the lowest i).
Because the region with the lowest average, Bin 0, overwrites all others, Bin 0’s multiplier can be calculated as:

Our goal is to ensure that the multipliers and adjustments for all nodes in all teams are also the maximum of 1 on average. Since Mₙ is the multiplier for the nth ordered bin and Aₙ is the normalized average for the nth ordered bin. This can be easily solved:
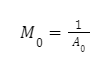
The next multiplier for Bin 1 can be calculated as the probability a node from Bin 1 is selected with a node from Bin 0 (which uses the M0 bin multiplier) and the probability that a node from Bin 1 is not teamed with a node from Bin 0 (which uses the M1 team multiplier):
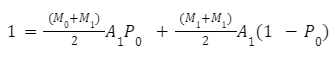
We can do the same calculation for Bin 2:
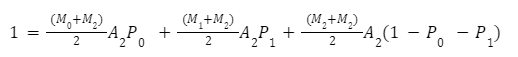
These equations, for any Bin, are solvable and can be defined in terms of the multiplier. For Bin 2, the transformations to calculate the multiplier are:
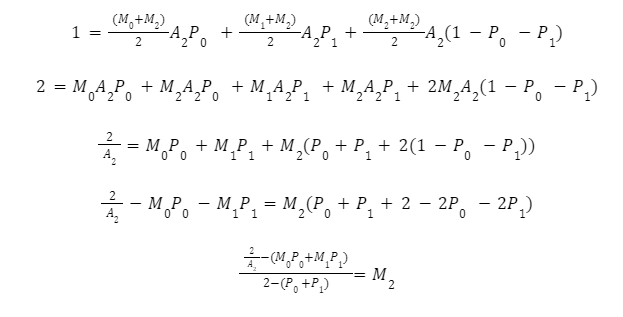
We can generalize this using summations for any team multiplier Bin n:
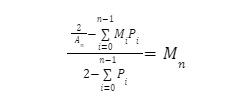
In addition to the recursive definition, the probabilities are tricky to get right. Each selection of a team of 5 nodes consists of a random draw, without replacement, from the total of nodes in the network. This sort of selection is described by a hypergeometric distribution. Most frequently, this distribution is applied to a simple case of counting objects (nodes in our case) with a binary feature (for example, in the BFT consensus realm: byzantine/honest nodes). However, in cMix we have split the nodes into 12 bins, which turns the problem into a multidimensional one, meaning that we need to calculate a multivariate hypergeometric distribution. Luckily, due to the nature of how multipliers work, when we are selecting a node from say, bin 2, we don’t care if any other node in the team is of a bin that has a higher multiplier. This means that all the probabilities that we need to compute are similar: we want to have a team with at least one node from bin i, without any nodes from all bins <i. We include a spreadsheet in our resources below which show how to do this in detail.
Error
This solution has some errors due to the fact that discrepancies in A values are in large part caused by variations in how long rounds take which impacts selection probabilities. This solution as described by our simulation is correct to within 3%. Future work can deconstruct the causes of point variations to better model them and reduce this error.
Resources:
List of bins:
Scheduling Algorithm: https://git.xx.network/xx_network/primitives/-/blob/dev/region/ordering.go
Multiplier Calculation:
https://docs.google.com/spreadsheets/d/1d2HcuCVorKDkUppBam-dk-_PJ8ukPp8ja18DyE_VYJQ/edit?usp=sharing
Python script for simulations to confirm calculations:


